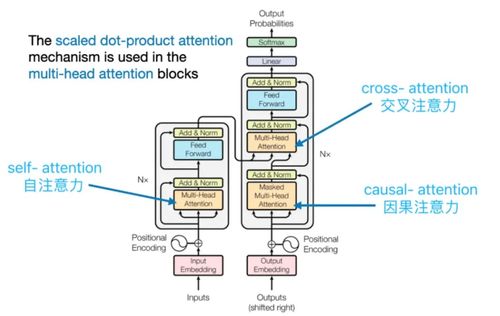
Transformer模型憑借其在自然語言處理等領域的卓越表現,已成為人工智能領域的核心架構。其成功背后,高效且強大的數據處理技術功不可沒。本文將通過動畫演示的視角,深入淺出地解析支撐Transformer高效運行的四大數據處理關鍵技術。
1. 分詞與詞嵌入(Tokenization & Embedding)
數據處理的第一步是將原始文本(如句子、段落)轉化為模型可以理解的數字形式。這一過程首先通過分詞技術,將連續的文本切分成有意義的單元(如單詞、子詞)。通過詞嵌入層,將這些離散的符號映射為高維空間中的連續向量。這個向量不僅包含了詞匯的語義信息,還為其在模型中的計算奠定了基礎。動畫可以生動展示一個句子如何被拆分成一個個Token,并像查表一樣轉換為一個個富含語義的向量。
2. 位置編碼(Positional Encoding)
Transformer模型摒棄了循環神經網絡(RNN)的順序結構,其自注意力機制本身不具備感知單詞順序的能力。因此,位置編碼技術至關重要。它通過為每個詞向量添加一個包含其位置信息的獨特向量,將序列的順序信息顯式地注入模型。常用的方法是使用正弦和余弦函數來生成這些位置向量。動畫可以形象地展示這些如同“波紋”或“條形碼”的位置向量是如何逐位疊加到詞嵌入向量上,讓模型“知道”每個詞在句子中的先后次序。
3. 掩碼(Masking)
在訓練過程中,尤其是在處理序列生成任務(如機器翻譯、文本摘要)時,模型需要遵循“不能偷看未來信息”的原則。掩碼技術在此扮演了關鍵角色。它通過在注意力權重矩陣的上三角區域(代表“未來”的詞)填充一個極大的負值(如負無窮),再經過Softmax函數后,這些位置的注意力權重幾乎變為零,從而屏蔽了未來詞對當前詞的影響。動畫可以清晰地演示一個注意力矩陣如何通過掩碼操作,從全連接狀態變為只關注當前位置及之前歷史信息的“下三角”有效區域。
4. 批處理與填充(Batching & Padding)
為了充分利用GPU等硬件的并行計算能力,提高訓練效率,模型通常同時處理多個樣本,即批處理。一個批次內的文本序列往往長短不一。為了解決這個問題,填充技術被引入:將較短的序列末尾添加特定的填充符號(如[PAD]),使其長度與批次內最長的序列保持一致,從而形成一個規整的張量。在計算注意力或損失時,需要忽略這些填充符號的影響。動畫可以展示不同長度的句子如何被“對齊”到同一長度,組成一個整齊的矩陣送入模型,以及注意力機制如何“忽略”那些填充部分。
分詞嵌入、位置編碼、掩碼以及批處理與填充,這四大數據處理技術如同精密的齒輪,協同工作,為Transformer模型提供了結構規整、信息完備的輸入數據,是其強大性能不可或缺的基石。通過動畫形式的揭秘,這些看似復雜的技術原理變得直觀易懂,讓我們得以一窺現代深度學習模型高效運轉背后的數據藝術。